6. 技術資料
6.1. MLSDK と MN-Core の関係
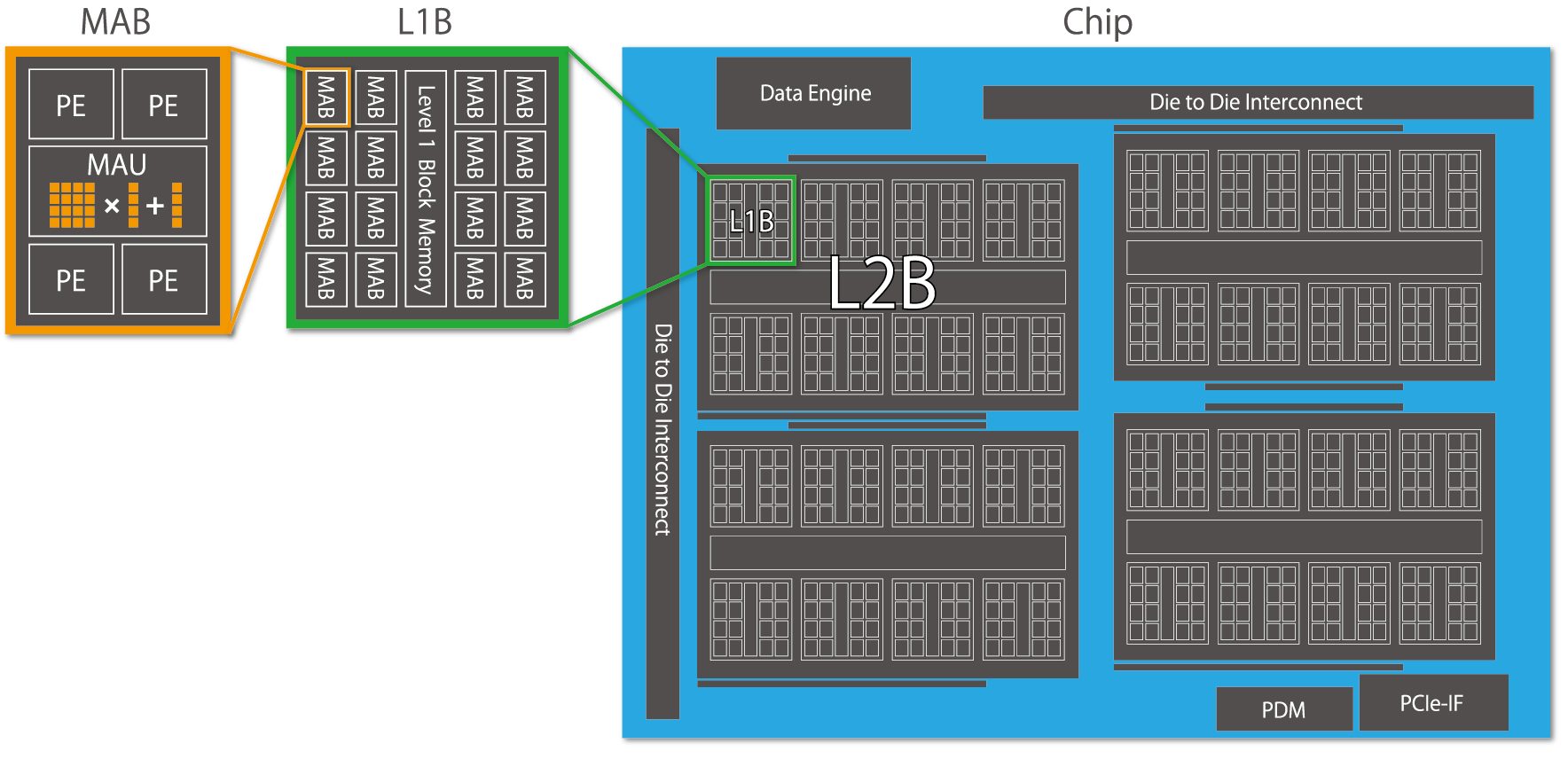
図 6.1 MN-Core's hierarchical architecture
MN-Core シリーズにおける最大の特徴は、 図 6.1 に示すような階層的な構造です。各 Processing Element (PE) は Local Memory (LM) や General Register File (GRF) を個別に持ち、それらはツリー状のメモリ階層の葉に相当します。特に LM は PE から高速にアクセスできる SRAM でありながら総容量が大きいため、 DRAM へのアクセスを最小限に抑えることができ、実質的な B/F 比の向上に貢献します。その一方でキャッシュメモリなどの高度なメモリ管理機能はなく、全てのデータ移動は明示的に指定する必要があります。MN-Core 2 自体について更に詳しく知りたい場合、 mncore2_dev_manual_ja.pdf を参照してください。
MLSDK から PyTorch のバックエンドとして MN-Core 2 を利用する場合、アセンブリ命令や命令フォーマットなどの知識は必要ありませんが、計算グラフの入出力や中間結果の Tensor がどのようにメモリを使用するかを知っておくことで、MLSDK をより高度に活用できます。それぞれの Tensor を MN-Core 2 内部のメモリに保存する際、MLSDK のグラフコンパイラ (codegen) が決定することは、大きく分けて以下の3点です。
まず、Dtype については基本的に元の Tensor の精度が反映されますが、行列積や畳み込み演算では一時的に精度を落として高速に演算を行います。逆に演算精度が求められる BatchNormalization などの処理では、精度を戻して演算します。この仕組みを混合精度演算と呼び、PyTorch では torch.amp として実装されているように、機械学習のフレームワークでは広く採用されています。また、codegen においては計算速度以外にも、Tensor の保存に必要な LM が少なくなるという利点があるため、グラフ全体で各 Dtype を管理し、数値精度をなるべく一定に保っています。
次に、Location と Layout については、元の Tensor の shape や先に設定された Dtype を考慮して設定されます。計算結果が複数の場所で再利用されるケースや、個別の計算処理で複数のマッピングを使用するケースがあるため、各 Tensor に対して MNValue と呼ぶ構造体を用意し、それに Location や Layout の情報を付与します。それぞれの情報を決定する仕組みは Dtype と比べて複雑なため、詳細については Location Planner と Layout Planner で説明します。また、Location と Layout の設定はどちらも LM 消費量と直接関係するため、それぞれがプランニングに影響を与えます。更に shape とそれを表現する Layout によっては、そもそも LM の容量に収まらないこともあります。その場合は Time-Slice を適用し、複数回に分割して処理することになります。
現在の codegen では以上3点の相互作用を考慮し、以下の順番で Dtype, Location, Layout を決定しています。
Dtype Planner : 数値精度を決定し Tensor の LM 消費量を大まかに決定
Location Planner (initial) : モデルのパラメータなど、確実に DRAM に配置する Tensor を決定
Layout Planner : 計算ノード (MNNode) の要求に従い、MNValue が DRAM と LM のどちらに配置されるかも考慮しつつ、Layout を決定
Location Planner : Layout から算出される LM 消費量も考慮しつつ Location を決定
Time-Slice : LM の容量を超過しつつも MNNode の要求により LM に配置する MNValue に対し、時分割を行って複数回に分割する
Location Planner (sliced) : 分割の影響を Location に反映する
このようにして codegen が管理する計算グラフ (MNGraph) と、それを構築する MNNode 及び MNValue の情報が決定された後、全体のスケジューリングを Scheduler が決定します。基本的な計算順序は計算グラフをトポロジカルソートして決定されますが、それに加えて MNValue を設定された Location に配置する順番も考慮する必要があります。MNValue の Location は、MNNode がその配置を前提に処理することを保証していますが、複数の場所で MNValue が再利用される場合など、LM にデータを置き続けることが出来ないケースもあります。その場合、データは一旦 DRAM へ退避することになり、計算処理のどのタイミングで退避するかなどは Scheduler が決定します。
例えば、最もナイーブな Scheduler に always_from_dram があります。これは計算結果の MNValue をすべて DRAM に書き戻し、再び必要になった時に DRAM から読み込む方式です。このスケジューリングは大抵のケースで動作しますが、明らかに最適なスケジューリングではなく、主にデバッグを目的としたものです。そのため、MLSDK は用途に合わせて複数の Scheduler を提供しており、ユーザーはそこから目的にかなったものを選択することができます。
また、最適なスケジューリングには、高度な Scheduler を用いるのに加えて、各 MNNode の実行速度やメモリ使用量についての情報が必要です。この情報を集める仕組みが Node Simulation であり、各 MNNode を様々な設定でコンパイルした結果を集計します。例えば、ある MNNode においてメモリ使用量と実行速度にトレードオフがある場合、メモリを節約した結果と、潤沢に使った結果をそれぞれ参照・比較することで、Scheduler は全体最適を目指した設定を選べます。
スケジューリングの後は各 MNValue に対して Address などを追加で設定し、各 MNNode に対応した Operator を Code Emit することで具体的なアセンブリを出力します。これらを順序通り結合することで、最終的なアセンブリと GPFNApp と呼ぶコンパイル結果が得られます。現行の MLSDK ではスケジューリング以降の処理について、ユーザー側で把握すべきことは多くありませんが、未対応の Operator を追加するなどの機能拡張を行えるよう準備を進めています。
さて、ここまでで MLSDK に入力された計算グラフがコンパイルされ、再利用可能な結果 (GPFNApp) を出力するまでについて説明しました。GPFNApp は MLSDK によって読み込まれ、 mlsdk.CompiledFunction として Python 側から呼び出すことができるため、コンパイル元の関数をこれで置き換えることで MN-Core 2 が使えます。先述した Node Simulation や Scheduler の処理に時間がかかるため、 MLSDK は GPFNApp の再利用が前提の設計であり、学習ループやバッチ推論といった同じ計算を繰り返すワークロードに適しています。また、データを MNValue としてツリー状の LM にマッピングする都合から、広範囲にわたって Indexing を行うような処理は不得意ですが、空間的局所性の高い演算であれば基本的に得意としています。
6.2. MLSDK Pipeline
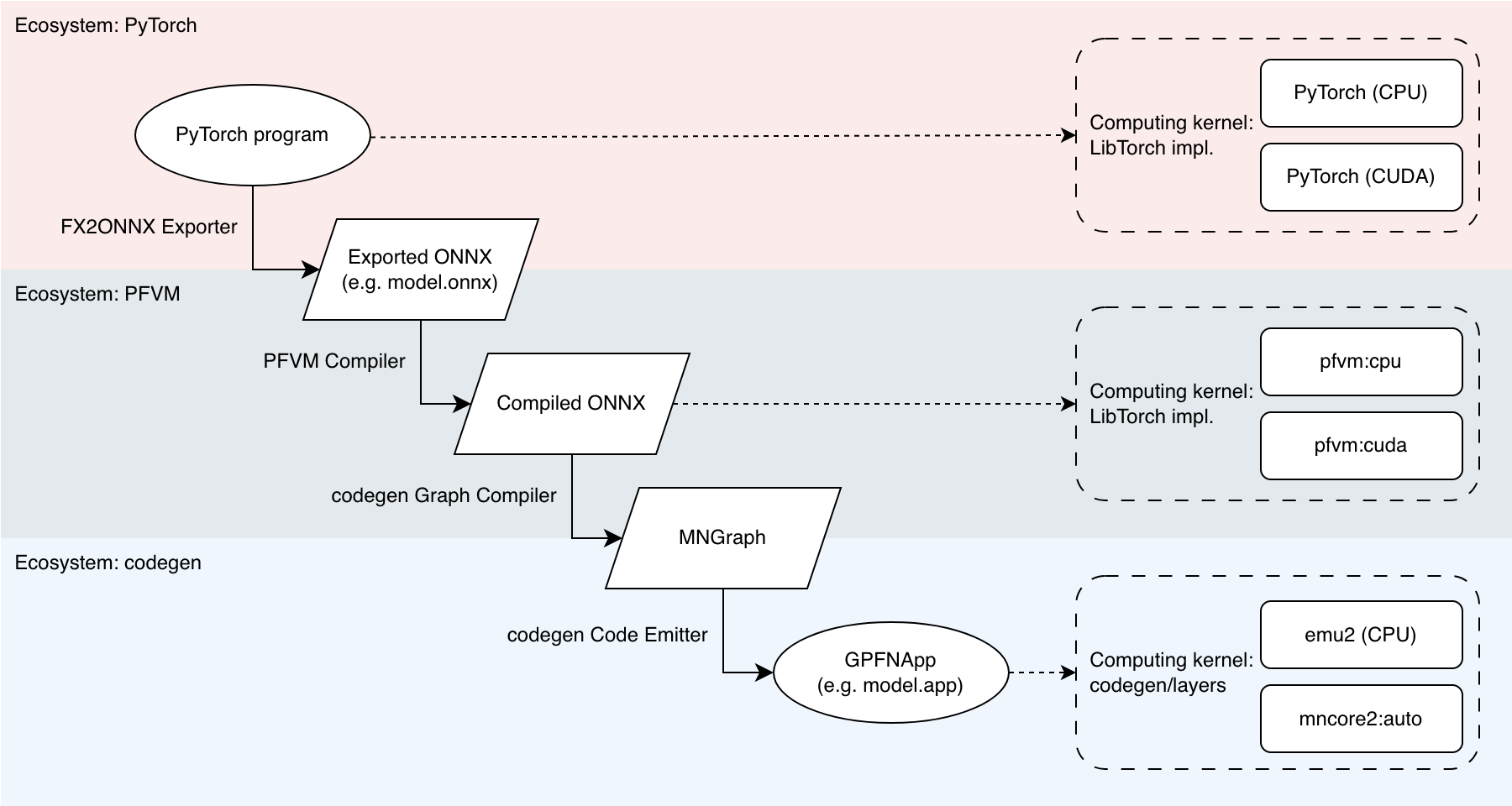
図 6.2 MLSDK Pipeline and Backend Correspondence
MLSDK は入力 (PyTorch program) を MN-Core シリーズ用にコンパイルする際、 図 6.2 に示すようにいくつかの変換を通して実行用のバイナリ (GPFNApp) を出力します。ここでは図中に登場する用語について説明します。
6.2.1. Ecosystem
MLSDK では、PyTorch プログラムを MN-Core シリーズで動作させるまでに複数の中間状態を経由します。それぞれの中間状態は ONNX などの形式で出力できる他、段階によってはそのまま実行することもできます。実行する環境には PyTorch, PFVM, codegen の3種類があり、これらについて概要を説明します。
PyTorch
torch を始めとして torch-vision などの関連のパッケージも含んだ環境を指します。
MLSDK は入力プログラムが torch.Tensor を使って計算処理を実装していることを前提にしており、その部分を計算グラフ (図中の Exported ONNX) としてエクスポートします。MLSDK の理念として torch.Tensor を使った記述そのものに制限はありません。
ただし、 torch パッケージに関しては MLSDK 用の拡張を含めてビルドしたものをインストールしているため、同一の MLSDK 環境でバージョンを使い分けることは現在出来ません。同様の理由で、外部からダウンロードした torch パッケージをインストールして使うことは出来ません。
PFVM
PFVM とは Exported ONNX を対象とした、コンパイラとランタイムを併せ持つ環境です。PyTorch プログラムから ONNX 形式で計算グラフを出力する、 FX2ONNX Exporter との連携が前提になっており、その際に重みの更新に関する処理など、元のプログラムに足りない要素を ONNX のカスタムオペレータとして Exported ONNX に追加しています。
PFVM によるコンパイル結果は ONNX を元にした構造体 (図中の Compiled ONNX) として出力し、パイプライン後段の codegen に渡します。Compiled ONNX は PFVM のランタイムで実行することもでき、MLSDK においては mlsdk.MNDevice の引数に pfvm:cpu や pfvm:cuda を指定することで、それぞれ CPU と GPU が使われます。この際、計算グラフ中の各オペレータは LibTorch を利用して実装されています。
codegen
codegen は Compiled ONNX を対象とした、MN-Core シリーズ専用のコンパイラとランタイムを併せ持つ環境です。コンパイル作業は大きく2段に分かれており、前段を codegen Graph Compiler 、後段を codegen Code Emitter と呼んでいます。codegen Graph Compiler は Compiled ONNX に対して MN-Core シリーズ専用オペレータの追加や、再計算も含めたスケジューリングを行った、 MNGraph を出力します。ちなみに、 MNGraph も ONNX を元にした構造体であるため、その形式でファイル出力することができます。
次に codegen Code Emitter は MNGraph 中の各オペレータに対してアセンブリの出力を行い、実行に必要な情報を付与して GPFNApp を出力します。この際、各オペレータの実装は図中の codegen/layers と呼ぶところにまとめています。
注釈
codegen/layers の実装は現時点では MN-Core SDK イメージに含まれておらず、 codegen のビルド済みライブラリに組み込まれています。
このようにして得られた GPFNApp は codegen 内部のランタイムによって MN-Core 2 で実行される (mncore2:auto) 他、エミュレータ (図中の emu2) と呼ぶ環境でも実行できます。emu2 は MN-Core 2 の仕様を可能な限り再現したソフトウェアであり、MN-Core 2 へのアクセスがない場合においても開発やデバッグを可能にします。CPU で動作を模倣するため、実機と比較すると非常に低速であることに注意してください。
補足
MN-Core シリーズへ移植するうえで PFVM を経由する利点について説明します。
まず、計算グラフへの変更量が非常に多く、その正しさを保証するのが比較的難しいのが PFVM Compiler による処理です。その前後の変更は比較的正しさの保証がしやすいため、計算グラフの種類を PyTorch Graph と Compiled Graph の2種にわけます。次に、各オペレータの実装の種類は LibTorch と codegen/layers の2種に分けることができます。
このように分けると、それぞれのエコシステムの対比は以下のようになります。
PyTorch: (PyTorch Graph) を (LibTorch) で処理
PFVM: (Compiled Graph) を (LibTorch) で処理
codegen: (Compiled Graph) を (codegen/layers) で処理
PyTorch から codegen へ直接進むとグラフとオペレータ実装の両方が変わりますが、PyTorch → PFVM と PFVM → codegen の段階を踏むことで、グラフとオペレータ実装をそれぞれ検証することができます。また、仮に codegen/layers には一切の問題がないとしても、 Compiled Graph に問題があればその後にも必ず影響があるため、PFVM の段階で止めて検証を進めるほうが効率が良いです。そのため、動作検証の際には pfvm:cpu, pfvm:cuda を一度試して計算結果を確認し、グラフ変換の部分で問題が起きていないか確認することをおすすめします。
6.2.2. Pipeline Stage
PyTorch program -- (FX2ONNX Exporter) -> Exported ONNX
FX2ONNX Exporter とは torch.fx の機能を活用して ONNX を出力する仕組みです。PFVM や codegen とは独立したコンポーネントであり、 /opt/pfn/pfcomp/fx2onnx に Python による実装があります。
FX2ONNX Exporter は mlsdk.Context.compile() に渡された関数オブジェクトに対して適用されます。その関数は Callcable[[Dict[str, Tensor]], Dict[str, Tensor]] の型であることが要求され、各入出力の torch.Tensor を起点にシンボリックトレースが行われます。トレースの結果得られる torch.fx.Graph には LibTorch 用のオペレータが含まれるため、これを ONNX のオペレータに変換して Exported ONNX を得ます。
注釈
トレースの過程では torch.Tensor は torch._subclasses.fake_tensor.FakeTensor として扱われるため、実際の計算処理は行われません。入力が torch.Tensor であるかを分岐条件にしている場合、正しく分岐のトレースが出来ない可能性があります。
PyTorch のプログラムを ONNX に変換する仕組みは、この他に torch.onnx によるものがあります。MLSDK では環境変数 MNCORE_USE_LEGACY_ONNX_EXPORTER を設定することで、 torch.onnx を ONNX の出力に使うこともできますが、現在は非推奨な機能でサポートは限定的です。ただし、一部の Examples では使用される可能性があります。
Example usage of torch.onnx:
$ cd /opt/pfn/pfcomp/codegen/examples/
$ MNCORE_USE_LEGACY_ONNX_EXPORTER=1 ./exec_with_env.sh python3 add.py
References:
Exported ONNX -- (PFVM Compiler) -> Compiled ONNX
PFVM Compiler とは Exported ONNX を入力とし、 Constant Propagation や Common Subexpression Elimination などの基本的な最適化から、 Operator Fusion や各種バックエンド専用のオペレータで置き換えるなどの高度な最適化を行う仕組みです。これらの最適化により Compiled ONNX を対象とした処理は、元の ONNX と比べて速度とメモリ消費量の両面で有利になります。MLSDK においては、 Compiled ONNX はデフォルトでは codegen_dir に保存しませんが、コンパイルオプションに --out_onnx=<out_onnx_path> を指定することで任意のパスへ出力することができます。
Compiled ONNX -- (codegen Graph Compiler) -> MNGraph
codegen Graph Compiler とは Compiled ONNX を入力とし、以下の項目についてグラフ全体で整合性を取ったうえで、計算順序を最適化した結果を MNGraph として出力する仕組みです。Compiled ONNX の段階ではグラフの一部に Dynamic Shapes が入っていることがありますが、グラフそのものの入出力に Dynamic Shapes が含まれるものは現在サポートしていません。また、 MNGraph として出力される段階では全ての Shape が Static となります。
計算グラフを MN-Core シリーズで処理するのに設定する項目:
Dtype: 各 MNValue の数値精度
Location: モデルの Parameters や Buffers、もしくは中間結果が DRAM と LM のどちらに位置するか
Layout: 様々な Shape を持つ各 MNValue が、MN-Core シリーズのメモリ階層にどのようにマッピングされるか
これらの整合性を取るにあたって、直前の設定を引き継ぐことができれば問題ないですが、実装の都合や計算精度の確保など、そのまま引き継げないケースがあります。そのような場合は、以下に示すような処置が必要になります。
Dtype の不整合: Cast 処理を挟む
Location の不整合: MNCoreUpload/MNCoreDownload オペレータを挿入して MNValue を移動する
Layout の不整合: MNCoreLayoutSwitch を挿入してレイアウトを切り替える
また、Local Memory (LM) の容量制限から一部の巨大な演算については、複数回に分けて処理 (時分割) する必要があります。この仕組みの詳細については Time-Slice を参照してください。
これらの項目が設定された後に、 Scheduler と呼ぶ仕組みが各演算の順序を決定します。利用可能なスケジューラは複数あり、それぞれデバッグ作業に向くものから高度な最適化をかけるものまであります。どのスケジューラを使用するかは コンパイルオプション から指定できます。
スケジューラの例:
always_from_dram: 演算が終わるたびに全ての MNValue を DRAM へ書き戻しますspill_opt: 次に使われる時期が最も遠い MNValue から DRAM へ書き戻しますauto_recompute_sa: 再計算も考慮してスケジューリングを行います
これらのスケジューラは各演算のメモリ消費と実行速度の情報を参考にします。
これらのスケジューラは各演算のメモリ消費と実行速度の情報を参考にします。特に auto_recompute_sa のような高度な最適化をかけるスケジューラは、正確かつ多様な設定での情報が必要です。そこで Node Simulation と呼ばれる、各演算が各設定でどれほどの性能かを見積もる仕組みがあります。Node Simulation にもいくつか設定があり、大まかな予想値を返す fake から、可能な組み合わせ全てを実際に Emit して試す best まであります。使用可能な設定については コンパイルオプション を参照してください。どれを選ぶべきかは使用するスケジューラにも関係するため、MLSDK に同梱されている Preset Options (/opt/pfn/pfcomp/codegen/preset_options) も参考にしてください。また、 best のような負荷の重い設定を採用する場合、 mlsdk.CacheOptions を設定して Node Simulation の結果を再利用することをおすすめします。
MLSDK は MNGraph の内容を l3ir.txt 及び l3ir_stripped.onnx (もしくは l3ir_stripped.onnx.zst) のファイル名で codegen_dir に保存します。l3ir.txt は MNGraph 中の各オペレータが計算順で記載されたものになっており、 l3ir_stripped.onnx は MNGraph を ONNX の形式で保存されたものになっています。ちなみに、 l3ir_stripped.onnx がストリップされたものは ONNX に付随する Initializer などのデータであるため、それ単体では計算内容の再現ができません。それらのデータを保存する役割は、次のステップで登場する GPFNApp が引き継ぎます。
MNGraph -- (codegen Code Emitter) -> GPFNApp
codegen Code Emitter とは MNGraph を入力とし、各演算の Emit 結果を計算順序通りに並べたものと、実行に必要な情報をまとめたものを合わせた GPFNApp を出力する仕組みです。
各演算の Emit 結果は、一部のアドレスが欠けた VSM のように表現されており、その時々の Context に応じて適切なアドレスが割り振られます (Relocation) 。Relocation に必要な情報は GPFNApp に含まれています。
6.3. codegen 用語集
6.3.1. codegen_dir
codegen_dir は mlsdk.Context.compile() の引数として指定するディレクトリです。標準入力及び標準エラー出力に表示されるログに加え、codegen のキャッシュを除く全ての出力は codegen_dir に保存されます。そのため、このディレクトリにはコンパイル時の再現に必要なほぼ全ての情報が含まれており、複雑な問題に直面した場合は、このディレクトリ (及び mlsdk.CacheOptions で指定したディレクトリ) を開発チームに共有していただくことを想定しています。
codegen_dir には以下の生成物が含まれます。これらについては、 Codegen Dashboard を利用することでブラウザから確認することもできます。
report.json: codegen の実行中に記録された各種データ各プロセス毎に記録されるため、コンパイルが途中で終了した場合でも正しく記録されています。
out.txt(out.json) : 上述したログが保存されています。out.jsonはout.txtを JSON 形式で保存したものです。model.onnx: FX2ONNX によって出力された ONNXmodel.app: コンパイル結果 (GPFNApp)model.vsm: コンパイル結果 (GPFNApp) の VSM のみを出力したものlayout.XXX(layout_XXX) : codegen Graph Compiler の各種プランナーによって加工後の MNGraph を出力したテキスト基本的にはプランナー開発者のための出力ですが、例外的に Time-Slice 処理によって MNNode, MNValue が分割される直前の MNGraph を記録した
layout.time_slice.txtは特に有用です。分割処理後は MNGraph 内部のノード数が大幅に増加するためです。
l3ir.txt: 最終的な MNGraph をスケジュールの順番通りに出力したテキストl3ir_stripped.onnx: 最終的な MNGraph を ONNX 形式で出力したもの元の ONNX に含まれていた Tensor データなどは削除されています。
simulation_result.json: Node Simulation の結果を保存したものtrace.json: MNGraph 中の各計算ノードの処理にかかる時間をプロファイリングしたもの (Perfetto UI)
6.3.2. MNGraph
MNGraph とは ONNX を codegen Graph Compiler 用に拡張したものです。PFVM から Compiled ONNX を受け取って初期化し、自身を ONNX 形式で出力することができますが、内部的には MNNode と MNValue からなる計算グラフとして表現しています。グラフコンパイル時には、各種プランナーが各 MNNode, MNValue を更新し、最終的に Code Emit 時に必要な情報が揃うようになっています。
MNGraph は計算順序を全 MNNode の配列として持っており、その内容をテキストとして出力する際は、その順序通りに MNNode と MNValue を以下のように並べます。
MNCoreDownload(x) -> (x_Download_1)
in(0):x onnx_type=Tensor(dtype=FLOAT32 shape=3,4) num_lw=4 padded_shape=3,8 layout=PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} layout_kind=MNCore dtype=Float gene=[,] loc=DRAM addr=0)
out(0):x_Download_1 onnx_type=Tensor(dtype=FLOAT32 shape=3,4) num_lw=4 padded_shape=3,8 layout=PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} layout_kind=MNCore dtype=Float gene=[,] loc=LM0 addr=0)
MNCoreDownload(y) -> (y_Download_1)
in(0):y onnx_type=Tensor(dtype=FLOAT32 shape=3,4) num_lw=4 padded_shape=3,8 layout=PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} layout_kind=MNCore dtype=Float gene=[,] loc=DRAM addr=16)
out(0):y_Download_1 onnx_type=Tensor(dtype=FLOAT32 shape=3,4) num_lw=4 padded_shape=3,8 layout=PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} layout_kind=MNCore dtype=Float gene=[,] loc=LM0 addr=8)
...
このログの意味するところは、このようになります。
MNNode
MNCoreDownloadによって DRAM に存在する MNValuexを LM0 に存在する MNValuex_Download_1へコピーMNNode
MNCoreDownloadによって DRAM に存在する MNValueyを LM0 に存在する MNValuey_Download_1へコピー
計算グラフの入力は DRAM に置かれており、それを PE で計算するために LM まで持ってくる最初の処理を表現していることがわかります。ここから更に MNNode 及び MNValue の持つ情報を読み取りたい場合、それぞれの項目を参照してください。
6.3.2.1. MNNode
PFVM, codegen が追加したカスタムオペレータ含む ONNX のオペレータに対応し、その入出力として MNValue の配列を持ちます。例えば MNCoreDownload は1入力1出力のオペレータであるため、ログには in(0):x と out(0):x_Download_1 が続けて出力されています。MNNode 自身は Code Emit 時に必要な情報をあまり持っておらず、代わりに MNValue が Dtype を始めとして複数のフィールドを持ちます。
6.3.2.2. MNValue
MNNode の入出力を表現する構造体です。同時に ONNX 中の Tensor に対応する構造体でもありますが、同じ Tensor に対応する MNValue が DRAM と LM の両方に存在することもあります。例えば Exported ONNX の x については、対応するそれぞれの MNValue が x onnx_type=Tensor(dtype=FLOAT32 shape=3,4) と x_Download_1 onnx_type=Tensor(dtype=FLOAT32 shape=3,4) になります。これらは元の ONNX 上の x (Tensor(dtype=FLOAT32 shape=3,4)) の情報を引き継いでいることがわかります。また、それと同時にそれぞれの MNValue は個別の Dtype や padded_shape を持っており、Code Emit ではそちらの情報を参照します。
6.3.2.3. Dtype
各 MNValue のログに dtype=Float とあり、これが MNValue が個別に持つ Dtype に相当します。Example: Adding Two Vectors ではコマンドラインオプションに float_dtype=float が指定されているため、 torch.float32 の型に対して Float を設定していますが、計算グラフ中に GEMM 系のオペレータを含み、かつ float_dtype=mixed である場合は、その GEMM 前後の MNValue に Half が設定されることもあります。MNGraph 全体を見て個別の MNValue に Dtype を設定するコンポーネントを Dtype Planner と呼び、設定漏れや過剰な Cast の発行を防いでいます。
各 MNValue に設定される Dtype は以下の通りです。
Unknown: Not setHalf: Half-precision floating pointFloat: Single-precision floating pointFloat32: 32-bit single-precision floating pointDouble: Double-precision floating pointHalfBool: Half-word boolean valuesSingleBool: Single-word boolean valuesLongBool: Long-word boolean valuesInt8: 8-bit integerByte: 1-byte integerShort: Signed half-word integerUShort: Unsigned half-word integerInt: Signed single-word integerUInt: Unsigned single-word integerLong: Signed long-word integerULong: Unsigned long-word integer
注釈
半語 (half word)、単語 (single word)、長語 (long word) は MN-Core 2 上でそれぞれ 16-bit, 32-bit, 64-bit のデータとして表現される。
6.3.2.4. Location
Location はデバイス上のメモリ (DRAM, LM0/LM1, etc.) を指し、ログでは loc=DRAM や loc=LM0 と表現されます。GRF0/GRF1 や L1BM/L2BM に関しては、MN-Core 2 においては Location に設定されることはありません。また、Location がまだ確定していない段階では、設定可能な値を減らした Location Kind と呼ぶ表現を使います。Location Kind の取りうる値は DRAM, LM, IMM (即値), InOut (入出力) の4種類で、 IMM と InOut に関しては自明に定まるため、 loc_kind=DRAM もしくは loc_kind=LM が見るべき情報になります。
Location Planner は、既に Location が指定されている状況を除き、Location Kind を元にプランニングを行います。これは LM0 と LM1 の対称性を用いて考慮すべき状態数を減らすためであり、グラフコンパイルの終盤で Location Kind を元に Location が設定されます。ただし、 imm 命令が LM0 へ書き込めないなど、ハードウェアの制約により完全に対称とは言えないケースもあります。その場合は、MNNode 側の設定で Location の選択を制限することにより、不適切な Location が割り当てられないようにすることができます。
6.3.2.5. Layout
Layout は MNValue の LM へのマッピングを表現し、ログでは layout=PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} と表現されます。また、 padded_shape=3,8 は Layout から計算することで得られるため、同じ項目で扱います。
まず、ログからわかるように、DRAM 上の MNValue であっても、Layout は設定されていることに注意してください。DRAM - LM 間の転送については codegen 全体で統一された規則があり、 MNCoreDownload (DRAM→LM) とその逆操作である MNCoreUpload (DRAM←LM) はその規則を実装したものです。そして、 MNValue x の Layout は MNCoreDownload を適用後のマッピングを表現したもので、データ自体は DRAM 上にその規則に則って並んでいます。別の視点から見ると、ホスト上の Tensor x が MNValue x としてデバイスの DRAM へコピーされる時、Layout に基づいた転置処理が発生します。この転置は基本的にホストで行うため、入力がより大きいケースでは、性能の側面で注意が必要です。
話を戻して、Layout の記法について説明します。例として挙げたケースでは Layout がシンプルなため、別の例を紹介します。
(64,128)/((8_L2B:1,8:2),(16_MAB:1,2:1,4_PE:1); B@[L1B,W])
~~~~~~~~ ~~~ ~~~~~~~~ ~~~~~~~~~
1 2 3 4
Tensor の shape (原則 ONNX 上での shape と一致)
{size of address}:{stride}
3 の level が Addr であるような特殊ケース
8:2はアドレスが2進むと、64の軸が1つ進むことを意味する
{size of level}_{level}:{stride}, level ∈ {PE, W, Addr, MAB, L1B, L2B}
指定されたレベルにおけるテンソルの分配方式
16_MAB:1は128の軸が、16個の MAB で分割されていることを意味する
B@[{level},...]
指定されたレベルにおけるテンソルの放送方式
B@[L1B]はそれぞれの L1B で同じ値を持つことを意味する
B@[W]は例外的に dtype=(64-bit の型) であることを意味する。これはアドレスの最小単位が長語であることに由来する。
(8_L2B:1,8:2) のような括弧で区切られた部分を Axis と呼び、 Axis 内の 8_L2B:1 のようなカンマによって区切られた部分を Subaxis と呼びます。各 Axis と shape の各軸は対応しており、各軸に対して各 Subaxis の size の積をとったものが padded_shape です。また、全 Axis の Addr 軸の size の積を取ったものが num_lw です。ただし、Addr にはアライメント制約があるため、num_lw がその分大きくなることがあります。この num_lw が LM の容量 (MN-Core 2 では 2048) を超えてしまった場合、 Time-Slice などで MNValue を分割する必要があります。
Reference:
MN-Core におけるテンソルのメモリ配置レイアウト表現 <https://tech.preferred.jp/ja/blog/mn-core-tensor-layout/>`_
6.3.2.6. Gene
Gene (gene=[,]) は各 MNValue に対して、遠くのノードに関する情報を付与します。これは各種プランナーを適用するにあたり、対象の局所的な情報だけでは足りないことがあり、それを補うための情報です。例えば、行列積や畳み込みといった、Layout への制約が強いノードが Gene を伝播させることにより、遠くのノードが Layout を決定する際の参考にできます。
6.3.2.7. Address
Address (addr=0) は codegen Graph Compiler において Scheduler の後に決定されます。これは、各 MNValue の生存期間が決まるのがそのタイミングであるためです。
Address と Location が定まると、各 MNValue が VSM 上でどのように表現されるのかがわかります。今回の例を MN-Core Challenge の記法で表現すると、 x は $d[0:4] 、 x_Download_1 は $lm[0:8] (アライメント制約によりパディングされています) であることがわかり、これらと同時に存在する y は $d[16:20] 、 y_Download_1 は $lm[8:16] です。
6.3.3. Location Planner
MNNode は入出力の MNValue それぞれに対し、Location Kind が DRAM と LM のどちらが良いか、もしくはどちらでも良いかを指定することができます。Location Planner は各 MNNode の主張がなるべく衝突しないよう Location Kind を設定し、それでも衝突が発生した場合は MNCoreDownload もしくは MNCoreUpload を挟むことで、全 MNNode の主張を満たします。
実行速度の観点では、可能な限り Location Kind は LM であるべきですが、一方で LM の容量不足を招くこともあります。そのため、一部の MNValue は DRAM に置くか Time-Slice で分割が必要になり、どちらを選ぶべきかは周囲の状況も影響する問題です。
6.3.4. Layout Planner
MNNode は入出力の MNValue それぞれに対し、どのような Layout を設定するかを指定することができます。指定する内容は各 MNNode の特性に関係しており、行列積などの性能が重要なものは、指定した Layout を前提に実装を行いますが、Elementwise なものについては Layout が性能に影響しないため、周辺の Layout に合わせるよう指定することもあります。Layout Planner はこれらの要求に対してなるべく衝突を起こさないように Layout を設定しますが、発生した場合は MNCoreLayoutSwitch を挟むことで、全 MNNode の主張を満たします。
Layout Planner には複数種類あり、コンパイルオプションから指定することもできますが、基本的には Layout Planner Z (lpz) の指定で問題ありません。Layout Planner Z は MNCoreLayoutSwitch そのもののコストも考慮に入れながら Layout を決定するため、一部の MNCoreLayoutSwitch のコストが跳ね上がる可能性を減らすことができます。
6.3.5. Time-Slice
Time-Slice は LM 消費量 (num_lw) が LM の容量よりも大きくなってしまった MNValue を分割し、1回の処理にかかる LM 消費量を減らす手法です。Time-Slice の処理は以下の2回に分けて行われます。
MNValue の Layout に
Timeレベルの Subaxis を追加し、Addr の size をその分減らすMNValue を MNGraph 上で分割し、それに関連する MNNode も分割する。その後、分割した MNValue を結合 (計算の種類によっては縮約) するための MNNode を追加する。
ここでは例として、num_lm=16 の Layout (64)/((16:1,4_PE:1); B@[...] を持つ MNValue a に対する Neg (符号の反転) 処理を考えます。LM の容量を8としたとき、このままでは a が LM に乗り切らないため、 2_Time:1 の軸を上記の Layout に追加します。
(64)/((2_Time:1,8:1,4_PE:1); B@[...]
これで num_lw=8 となり、LM に乗り切るようになりました。具体的に a とそれを入力にする Neg の分割と結合について考えると、以下のようになります。
MNCoreInputSplitを追加してaを分割分割されたそれぞれの MNValue に対して
Negを適用それぞれの
Negの出力をMNCoreOutputConcatを追加して結合
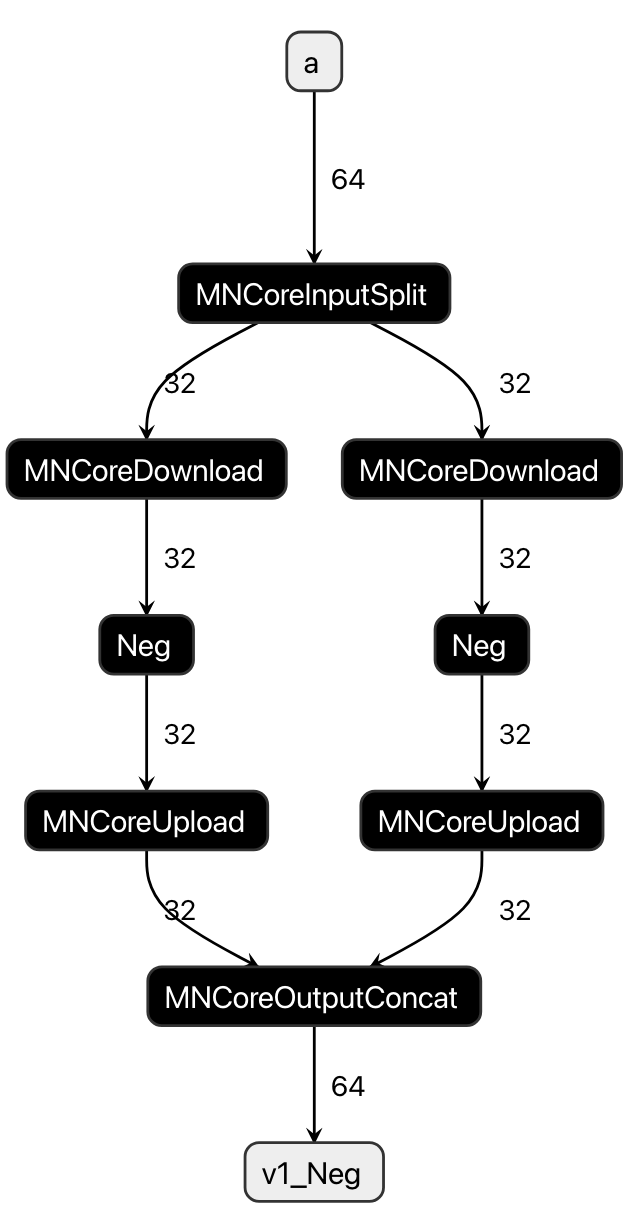
図 6.3 Time-Slice for a and Neg
6.3.6. Node Simulation
各 MNNode について、Code Emit した際のメモリ使用量と実行時間を、複数の設定で推定します。この結果は mlsdk.CacheOptions の enable_codegen_cache を有効にすることで再利用されます。
Node Simulation 時に変更されうる設定は以下の通りです。
Location (LM0 / LM1 もしくは入出力を in-place で更新するか)
Code Emit 後に入力 MNValue を破棄できるかどうか
一部の演算で利用可能な設定オプション (実装バリエーションを選択するためのもの)
6.3.7. Scheduler
Scheduler の仕事は以下の通りです。
算グラフに基づいて演算処理の実行順序を決定する
LM 上の値に対する命令 (DRAM 間のデータ転送、MNValue の Forget、LM0/LM1 間のデータ転送) を追加し、モデル計算を LM の容量内で実行可能にする
要に応じて再計算すべき演算処理を指定する
再計算は、計算コストの増加に伴うメモリ使用量とデータ転送コスト (LM と DRAM 間) を削減するための手法であり、特に SRAM 容量が制限されている MN-Core アーキテクチャにおいて、LM と DRAM 間のデータ転送コストが大きい場合に有効です。
6.3.8. Code Emit
codegen Code Emitter は、 MNGraph に設定された情報を参考に、以下の手順でアセンブリコードを出力します。
MNNode 毎にコンパイル
それぞれのコンパイル結果をリンクし、単一のアセンブリコードにまとめる
この内、2番の手順は Concat 戦略と Merge 戦略があり、最適化オプションによっては後者を使用します。
6.3.8.1. Concat
Address Planner が全ての MNNode / MNValue 間でアドレスの一貫性を保証するため、各 MNNode のコンパイル結果を単に連結することでリンク処理が完了します。
6.3.8.2. L1Merge
L1Merge は codegen のコンポーネントの1つで、2つの命令列を1つに統合することができます。これは例えば、DRAM - LM 間通信が多い命令列と、計算処理が多い命令列があった場合、それぞれ要求するリソースが異なるため、統合によって命令列が短くなることが期待できます。
この L1Merge を各コンパイル結果に対して繰り返し適用することで、基本的には単一のアセンブリコードにまとめることができます。しかし、入出力が inplace になっていたりなど適用できないケースがあり、その場合はアドレスの並び替え (MNCoreReorderAddress) などの処理が追加で必要になります。
6.3.9. GPFNApp
GPFNApp とは、アセンブリコード (VSM) とその実行に必要なデータを flatbuffers でまとめたオブジェクトです。codegen のコンパイル結果とも呼べるもので、MLSDK では mlsdk.Context.compile() 内部で GPFNApp を読み込んで実行準備完了としています。また、 mlsdk.CacheOptions を設定した際に保存されるものでもあります。
内容は大きく分けて以下の通りです。MLSDK に同梱されている /opt/pfn/pfcomp/codegen/build/integration/dump_gpfnapp というツールを使うことで、codegen_dir 内の GPFNApp の内容を確認することもできます。
VSM : バイナリ化済みのアセンブリコード。GPFNBin とも呼ぶ
入出力ノードの情報 : 名前に加えて Dtype, Layout, Address など
コンパイル元のモデルのパラメータ
GPFNBin を再配置するための情報 (reloc info.)
一部のフィールドは MLSDK では現在サポートしていないものもあります。