3. 移行作業チュートリアル
PyTorch プログラムに MLSDK を導入し、MN-Core シリーズに移行する手順について紹介します。
3.1. 移行手順
移行作業においては、段階を踏んで少しづつ MN-Core 2 で動く範囲を広げていくことが重要です。例えば、既に GPU など別のバックエンドで動作しているモデルの場合、学習済みのモデルを使った推論処理の移行から入り、その動作が確認できてから学習処理の移行を始めるのが良いです。
ここでは具体的な移行の手順について、 機械学習チュートリアル でも取り上げた MNCoreClassifier モデルを例に見ていきます。
48class MNCoreClassifier(torch.nn.Module):
49 def __init__(self):
50 super().__init__()
51 self.linear1 = torch.nn.Linear(1024, 256)
52 self.linear2 = torch.nn.Linear(256, 10)
53
54 def forward(self, x, t, **args):
55 x_reshaped = x.reshape(x.size(0), -1)
56 x1 = self.linear1(x_reshaped)
57 x2 = torch.nn.functional.relu(x1)
58 y = self.linear2(x2)
59 loss = torch.nn.functional.cross_entropy(y, t)
60 if self.training:
61 return {"loss": loss}
62 else:
63 return {"y": y, "loss": loss}
/opt/pfn/pfcomp/codegen/examples/ 以下にある mnist.py は、 MNCoreClassifier の学習と推論を同時に MN-Core 2 上で走らせるプログラムですが、それぞれの処理を PyTorch のみで記述したものが mnist_train.py と mnist_infer.py です。
これらを以下の順番で作業していきます。
移行元プログラムの動作チェック
pfvm:cpuでの動作確認mncore2:autoでの動作確認
3.1.1. 推論処理
16def main(checkpoint_path: str, outdir: str, option_json_path: Optional[Path], device_str: str) -> None:
17 batch_size = 64
18 eval_batch_size = 125
19
20 _, eval_loader = mnist_loaders(batch_size, eval_batch_size)
21
22 checkpoint = torch.load(checkpoint_path)
23
24 model_with_loss_fn = MNCoreClassifier()
25 model_with_loss_fn.load_state_dict(checkpoint["model_state_dict"])
26 model_with_loss_fn.eval()
27
28 def eval_step(inp: Mapping[str, torch.Tensor]) -> Mapping[str, torch.Tensor]:
29 x = inp["x"]
30 t = inp["t"]
31 output = model_with_loss_fn(x, t)
32 y = output["y"]
33 _, predicted = torch.max(y, 1)
34 correct = (predicted == t).sum()
35 return {"correct": correct}
36
37 correct = 0
38 for sample in eval_loader:
39 correct += eval_step(sample)["correct"]
40 print(
41 f"Correct: {correct} / {len(eval_loader.dataset)}. "
42 f"Accuracy: {correct / len(eval_loader.dataset)}"
43 )
44 assert 0.95 < correct / len(eval_loader.dataset)
mnist_infer.py の動作チェック
まず Example: Inference MNIST を参考に推論処理が PyTorch で走ることを確認します。学習済みのチェックポイントは、 Example: MNIST on MN-Core 2 を実行済みの場合 /tmp/mlsdk_mnist/checkpoint.pt に保存されています。
出力結果が学習終了時の推論結果と等しくなれば、動作チェックは完了です。
pfvm:cpu での動作確認
次に mnist.py を参考に、 eval_step をコンパイルして呼び出すように変更してみましょう。変更したスクリプトを実行する際は、 --device オプションに pfvm:cpu を指定することで、処理に PFVM のランタイムを使用できます。
更に、 --option_json を経由してコンパイルオプションを渡してみます。ここでは例として、 Compiled ONNX を出力させるよう --out_onnx を指定する JSON を以下に示します。特に mnist.py の記述から変えていなければ、 <codegen_dir> は /tmp/mlsdk_mnist_infer/eval_step となるはずです。
{
"args": [
"--out_onnx=<codegen_dir>/pfvm.onnx"
]
}
無事に実行が完了した場合、 codegen_dir 以下には model.onnx (Exported ONNX) と pfvm.onnx (Compiled ONNX) の2種類の ONNX が存在するはずです。これらの ONNX ファイルは Codegen Dashboard に組み込まれている Netron で可視化出来ます。
また、実行が異常終了する場合は mnist.py との差分や よくあるエラーと対処法 を参考に修正してください。実行は正常終了しても結果に異常がある場合、これらのモデル可視化を試すことで処理内容の差分を確認できます。
まず、 model.onnx を可視化した 図 3.1 を見てみましょう。
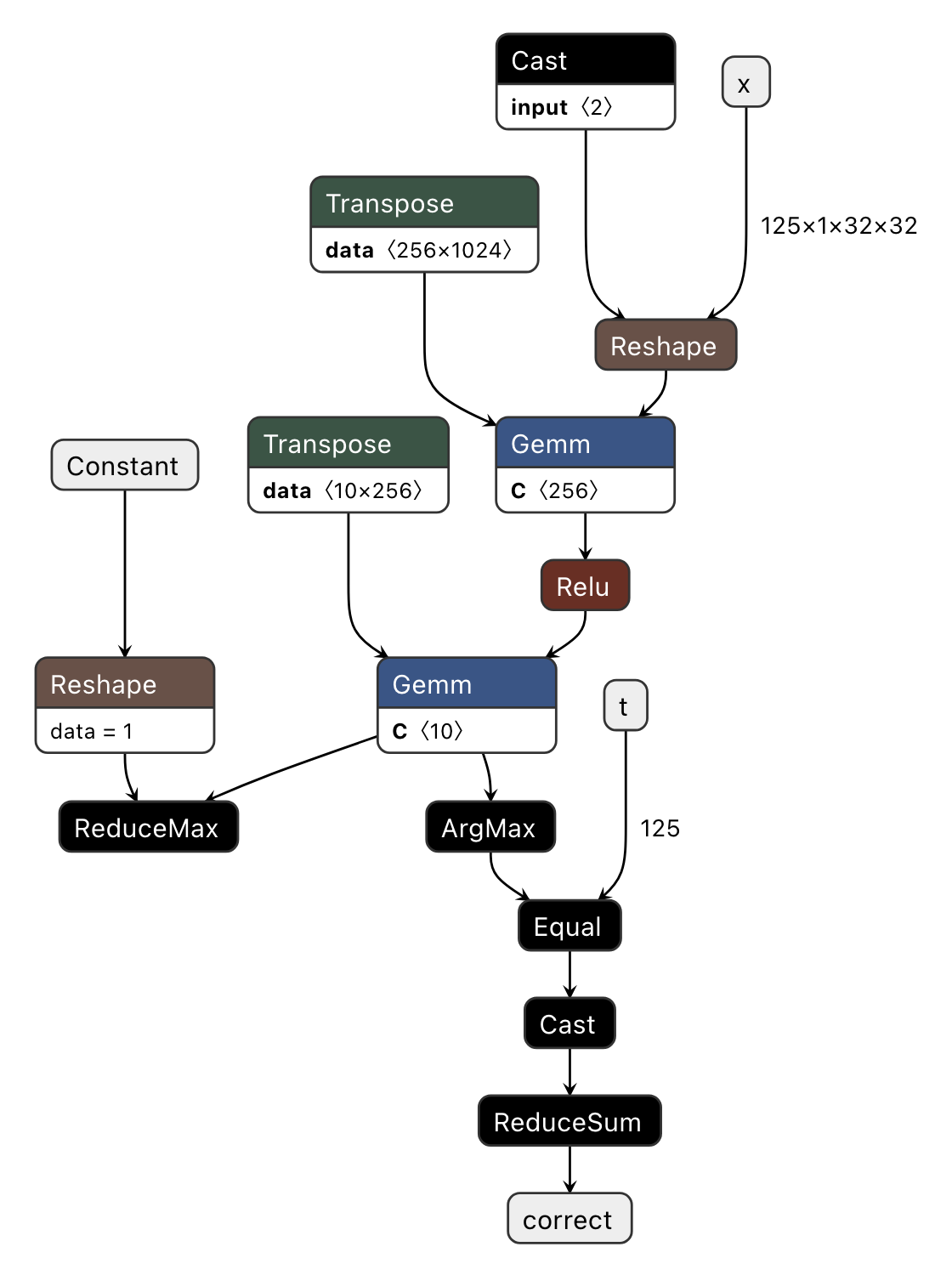
図 3.1 Visualizing model.onnx (Exported ONNX)
eval_step の入出力 (x, t, correct) がそれぞれ ONNX の入出力に対応していることのほか、 Transpose の出力が Gemm の右入力になっていることや、 torch.max の使われていない方の処理 (ReduceMax) が残っていることがわかります。このように、 Exported ONNX の段階では PyTorch の処理をそのまま辿ったような計算グラフとなっています。
この計算グラフを PFVM でコンパイルしたものが pfvm.onnx であり、今度はこれを可視化した 図 3.2 を見てみましょう。
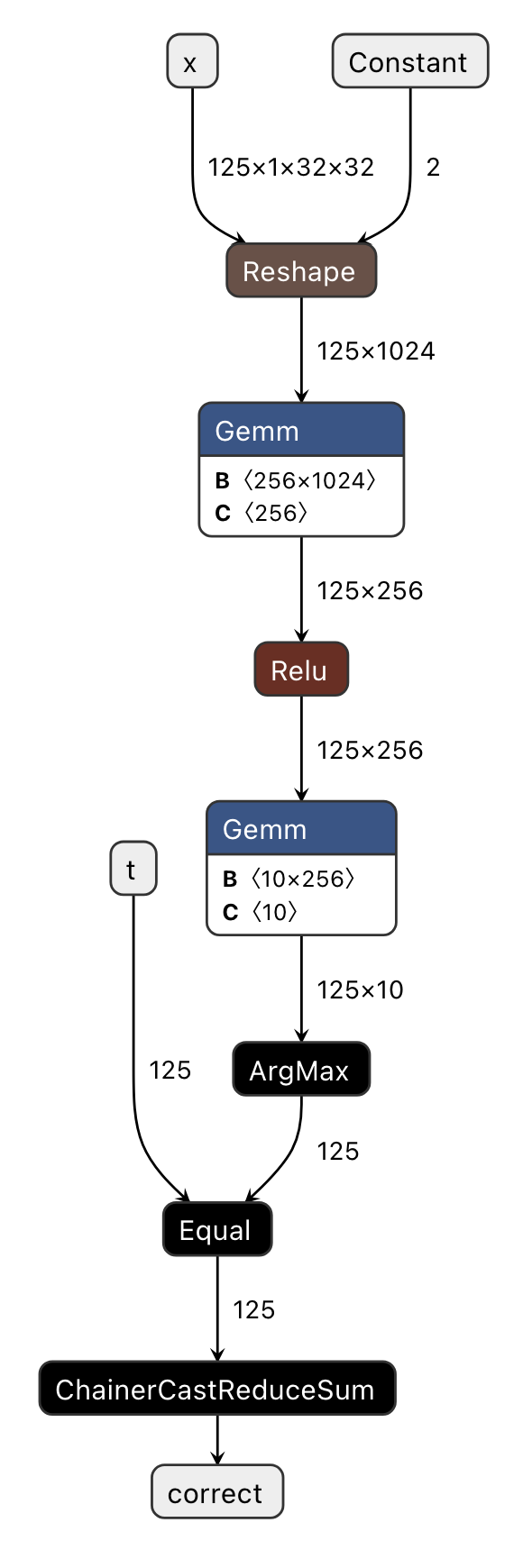
図 3.2 Visualizing pfvm.onnx (Compiled ONNX)
元の計算グラフに以下に示すような最適化が施され、簡潔なグラフになっていることがわかります。これにより、 CPU や MN-Core 2 ではなく PFVM のバックエンドに GPU (pfvm:cuda) を利用する場合においても、元の PyTorch プログラムよりメモリ消費及び実行速度で有利になります。
Reshapeのshape入力の定数化Operator Fusion
Gemm右入力のTransposeをtransB=1とすることで消去連続する
CastとReduceSumをまとめてChainerCastReduceSumで置き換え
結果が使われない
ReduceMax周辺の処理を消去
注釈
PFVM が加える ONNX のカスタムオペレータの多くは、名前のプリフィクスが MNCore もしくは Chainer となります。
このグラフと eval_step の実装を見比べ、ONNX に正しく反映されていない箇所がないかが確認できれば、可視化の目的は達成されています。
mncore2:auto での動作確認
最後に --device オプションに mncore2:auto を指定して、 eval_step が MN-Core 2 で動くか確かめてみましょう。
無事に実行が完了した場合、 codegen_dir 以下に l3ir_stripped.onnx.zst が存在するはずです。これを解凍 (zstd -d) し、 codegen-dashboard で同様に可視化した 図 3.3 を見てみましょう。
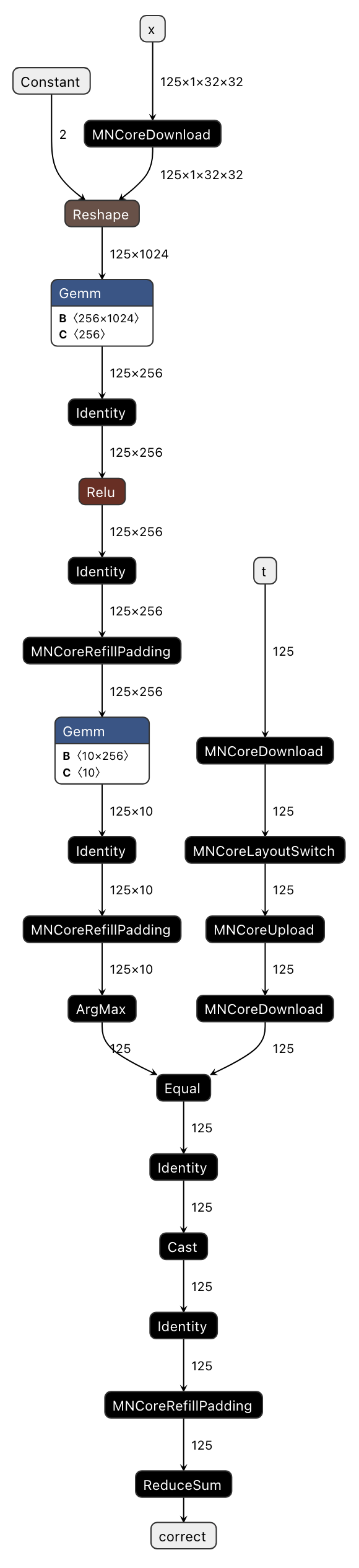
図 3.3 Visualizing l3ir_stripped.onnx (MNGraph)
図 3.2 と比較すると、 基本的に l3ir_stripped.onnx は pfvm.onnx にカスタムオペレータを足したものになっていることがわかります。
この例で足されているカスタムオペレータ一覧:
MNCoreUpload/MNCoreDownload: MNValue を LM → DRAM (Upload)、もしくは DRAM → LM (Download) 方向に移動するMNCoreLayoutSwitch: MNValue の Layout を変換するIdentity: MNValue を反対側の LM へ移動する (LM は LM0 と LM1 の2種類)MNCoreRefillPadding: Layout に含まれる Padding 部分に設定された値 (例: kZero, kInf) を書き込む
また、 MNGraph には各オペレータをどの順番で実行するかの情報も含んでいます。この情報は codegen_dir 以下の l3ir.txt にまとまっており、この例では以下のような内容になっています。
Constant() -> (val_1_fx2onnx)
out(0):val_1_fx2onnx onnx_type=Tensor(dtype=INT64 shape=2) num_lw=2 padded_shape=8 layout=PadLayout{(2)/((8_L1B:1); B@[PE,W,MAB,L2B])} layout_kind=MNCore dtype=Int gene=[] loc_kind=IMM loc=IMM)
MNCoreDownload(t) -> (t_Download_1)
in(0):t onnx_type=Tensor(dtype=INT64 shape=125) num_lw=2 padded_shape=128 layout=PadLayout{(125)/((8_L2B:1, 8_L1B:1, 1:1, 2_W:1); B@[PE,MAB])} layout_kind=MNCore dtype=Int gene=[Nr] loc=DRAM addr=0)
out(0):t_Download_1 onnx_type=Tensor(dtype=INT64 shape=125) num_lw=2 padded_shape=128 layout=PadLayout{(125)/((8_L2B:1, 8_L1B:1, 1:1, 2_W:1); B@[PE,MAB])} layout_kind=MNCore dtype=Int gene=[Nr] loc=LM0 addr=0)
MNCoreLayoutSwitch(t_Download_1) -> (t_LayoutSwitch_0)
in(0):t_Download_1 onnx_type=Tensor(dtype=INT64 shape=125) num_lw=2 padded_shape=128 layout=PadLayout{(125)/((8_L2B:1, 8_L1B:1, 1:1, 2_W:1); B@[PE,MAB])} layout_kind=MNCore dtype=Int gene=[Nr] loc_kind=LM loc=LM0 addr=0)
out(0):t_LayoutSwitch_0 onnx_type=Tensor(dtype=INT64 shape=125) num_lw=2 padded_shape=128 layout=PadLayout{(125)/((8_L2B:1, 8_L1B:1, 2:1); B@[PE,W,MAB])} layout_kind=MNCore dtype=Int gene=[Nr] pad_type=Dirty loc_kind=LM loc=LM0 addr=4)
MNCoreUpload(t_LayoutSwitch_0) -> (t_LayoutSwitch_0_Upload_0)
in(0):t_LayoutSwitch_0 onnx_type=Tensor(dtype=INT64 shape=125) num_lw=2 padded_shape=128 layout=PadLayout{(125)/((8_L2B:1, 8_L1B:1, 2:1); B@[PE,W,MAB])} layout_kind=MNCore dtype=Int gene=[Nr] pad_type=Dirty loc=LM0 addr=4)
out(0):t_LayoutSwitch_0_Upload_0 onnx_type=Tensor(dtype=INT64 shape=125) num_lw=2 padded_shape=128 layout=PadLayout{(125)/((8_L2B:1, 8_L1B:1, 2:1); B@[PE,W,MAB])} layout_kind=MNCore dtype=Int gene=[Nr] pad_type=Dirty loc=DRAM addr=526869888)
MNCoreDownload(x) -> (x_Download_0)
in(0):x onnx_type=Tensor(dtype=FLOAT32 shape=125,1,32,32) num_lw=8 padded_shape=128,1,32,32 layout=PadLayout{(125,1,32,32)/((8_L2B:1, 8_L1B:1, 2:1), (), (16_MAB:1, 2:4), (2:2, 4_W:1, 4_PE:1))} layout_kind=MNCore dtype=Half gene=[N,,,] pad_type=Zero loc=DRAM addr=1024)
out(0):x_Download_0 onnx_type=Tensor(dtype=FLOAT32 shape=125,1,32,32) num_lw=8 padded_shape=128,1,32,32 layout=PadLayout{(125,1,32,32)/((8_L2B:1, 8_L1B:1, 2:1), (), (16_MAB:1, 2:4), (2:2, 4_W:1, 4_PE:1))} layout_kind=MNCore dtype=Half gene=[N,,,] pad_type=Zero loc=LM0 addr=0)
Reshape(x_Download_0, val_1_fx2onnx) -> (view_fx2onnx)
in(0):x_Download_0 onnx_type=Tensor(dtype=FLOAT32 shape=125,1,32,32) num_lw=8 padded_shape=128,1,32,32 layout=PadLayout{(125,1,32,32)/((8_L2B:1, 8_L1B:1, 2:1), (), (16_MAB:1, 2:4), (2:2, 4_W:1, 4_PE:1))} layout_kind=MNCore dtype=Half gene=[N,,,] pad_type=Zero loc_kind=LM loc=LM0 addr=0)
in(1):val_1_fx2onnx onnx_type=Tensor(dtype=INT64 shape=2) num_lw=2 padded_shape=8 layout=PadLayout{(2)/((8_L1B:1); B@[PE,W,MAB,L2B])} layout_kind=MNCore dtype=Int gene=[] loc_kind=IMM loc=IMM)
out(0):view_fx2onnx onnx_type=Tensor(dtype=FLOAT32 shape=125,1024) num_lw=8 padded_shape=128,1024 layout=PadLayout{(125,1024)/((8_L2B:1, 8_L1B:1, 2:1), (16_MAB:1, 4:2, 4_W:1, 4_PE:1))} layout_kind=MNCore dtype=Half gene=[N,C] pad_type=Zero loc_kind=LM loc=LM0 addr=0 parent=x_Download_0)
Gemm(view_fx2onnx, attr_0, attr_1, transB) -> (addmm_fx2onnx)
in(0):view_fx2onnx onnx_type=Tensor(dtype=FLOAT32 shape=125,1024) num_lw=8 padded_shape=128,1024 layout=PadLayout{(125,1024)/((8_L2B:1, 8_L1B:1, 2:1), (16_MAB:1, 4:2, 4_W:1, 4_PE:1))} layout_kind=MNCore dtype=Half gene=[N,C] pad_type=Zero loc_kind=LM loc=LM0 addr=0 parent=x_Download_0)
in(1):attr_0 onnx_type=Tensor(dtype=FLOAT32 shape=256,1024) num_lw=1024 padded_shape=256,1024 layout=PadLayout{(256,1024)/((16:64, 4_W:1, 4_PE:1), (16_MAB:1, 4:16, 4:1, 4:4); B@[L1B,L2B])} layout_kind=MNCore dtype=Half gene=[WC,WC] loc_kind=DRAM loc=DRAM addr=9216)
in(2):attr_1 onnx_type=Tensor(dtype=FLOAT32 shape=256) num_lw=2 padded_shape=256 layout=PadLayout{(256)/((16_MAB:1, 2:1, 2_W:1, 4_PE:1); B@[L1B,L2B])} layout_kind=MNCore dtype=Float gene=[WC] loc_kind=DRAM loc=DRAM addr=25600)
out(0):addmm_fx2onnx onnx_type=Tensor(dtype=FLOAT32 shape=125,256) num_lw=2 padded_shape=128,256 layout=PadLayout{(125,256)/((8_L2B:1, 8_L1B:1, 2:1), (16_MAB:1, 4_W:1, 4_PE:1))} layout_kind=MNCore dtype=Half gene=[N,C] pad_type=Dirty loc_kind=LM loc=LM1 addr=0)
...
l3ir.txt の内容を全て書き下す訳にはいかないため、上に示した範囲で各オペレータの説明をします。ちなみに、 MNGraph では各オペレータを MNNode 、その入出力を MNValue と呼びます。例えば Constant() -> (val_1_fx2onnx) の表記では、 Constant が MNNode で val_1_fx2onnx が MNValue に相当します。また、 in(...): や out(...): は対応する MNValue の詳細説明になっています。
Constant() -> (val_1_fx2onnx):Reshapeに入力する定数を作成。Constantは他に依存がないため、通常一番最初にスケジュールされます。MNCoreDownload(t) -> (t_Download_1): 入力tを DRAM から LM へ移動MNCoreLayoutSwitch(t_Download_1) -> (t_LayoutSwitch_0):tのレイアウトを変更MNCoreUpload(t_LayoutSwitch_0) -> (t_LayoutSwitch_0_Upload_0): レイアウトを変更したtを DRAM へ移動MNCoreDownload(x) -> (x_Download_0): 入力xを DRAM から LM へ移動Reshape(x_Download_0, val_1_fx2onnx) -> (view_fx2onnx):xの ReshapeGemm(view_fx2onnx, attr_0, attr_1, transB) -> (addmm_fx2onnx): Reshape したxを入力に行列積
ここでは解説し切れないものも含めると、 l3ir.txt は MNGraph の持つ大半の情報を表現可能です。グラフのノード数が増えるにつれて ONNX の直接の可視化が難しいこともあり、 MNGraph の検証をするうえで重要なログファイルです。
さて、 mncore2:auto での実行が正しく行われることが確認出来た場合、より高度なスケジューリングを試すこともできます。コンパイルオプションに --scheduler を指定する例を以下の JSON に示します。
{
"args": [
"--scheduler=spill_opt"
]
}
これを適用して再実行した場合、同様に l3ir_stripped.onnx を可視化することで効果を確認することもできますが、最も直接的な指標は、 codegen_dir 以下にある report.json の vsm_cycles です。vsm_cycles は VSM 全体の実行にかかるサイクル数を意味しており、これを同じく report.json 中の core_freq (MHz 単位) で割ることで、実際にかかる時間が得られます。
執筆時のケースでは core_freq が 750.0 であり、 vsm_cycles がデフォルトのスケジューラ (reuse_consecutive) で 7500 (0.010 msec, 6.63 TFLOPS = 1.69%) 、 spill_opt スケジューラを使うことで 6932 (0.009 msec, 7.17 TFLOPS = 1.82%) まで高速化できました。MNCoreClassifier の推論処理自体の flops が report.json によると 66,273,875 と非常に小さいこともあり、 MN-Core 2 のパフォーマンスを十分に引き出すことはできませんが、実践的な状況ではより大きな効果を期待できます。
スケジューラなど高速化に関する設定については、コンパイルオプション や Preset Options を参照してください。
3.1.2. 学習処理
18def main(outdir: str, option_json_path: Optional[Path], device_str: str) -> None:
19 batch_size = 64
20 eval_batch_size = 125
21
22 train_loader, _ = mnist_loaders(batch_size, eval_batch_size)
23
24 model_with_loss_fn = MNCoreClassifier()
25 model_with_loss_fn.train()
26
27 optimizer = torch.optim.SGD(model_with_loss_fn.parameters(), 0.1, 0.9, 0.0)
28
29 def train_step(inp: Mapping[str, torch.Tensor]) -> Mapping[str, torch.Tensor]:
30 x = inp["x"]
31 t = inp["t"]
32 optimizer.zero_grad()
33 output = model_with_loss_fn(x, t)
34 loss = output["loss"]
35 loss.backward()
36 optimizer.step()
37 return {"loss": loss}
38
39 for epoch in range(10):
40 loss = 0.0
41 for i, sample in enumerate(train_loader):
42 curr_loss = train_step(sample)["loss"]
43 loss += (curr_loss - loss) / (i + 1)
44 if i % 100 == 0:
45 print(f"epoch {epoch}, iter {i:4}, loss {loss}")
46 print(f"epoch {epoch}, loss {loss}")
47
48 os.makedirs(outdir, exist_ok=True)
49 torch.save(
50 {
51 "model_state_dict": model_with_loss_fn.state_dict(),
52 "optim_state_dict": optimizer.state_dict(),
53 },
54 storage.path(outdir) / "checkpoint.pt",
55 )
mnist_train.py の動作チェック
まず Example: Training MNIST を参考に学習処理が PyTorch で走ることを確認します。学習結果は <outdir>/checkpoint.pt に保存されるため、 mnist_infer.py を利用して結果の検証が可能です。
Accuracy の値が 0.95 より大きければ、動作チェックは完了です。
pfvm:cpu での動作確認
次に mnist.py を参考に、 train_step をコンパイルして呼び出すように変更してみましょう。そして 推論処理 と同様に --device に pfvm:cpu を指定し、コンパイルオプション --out_onnx の設定もしておきます。
無事に実行が終了していれば codegen_dir 以下に Compiled ONNX に相当する ONNX ファイルがあります。これを可視化した 図 3.4 は以下のようになります (Exported ONNX との関係は上で説明したため、省略します)。
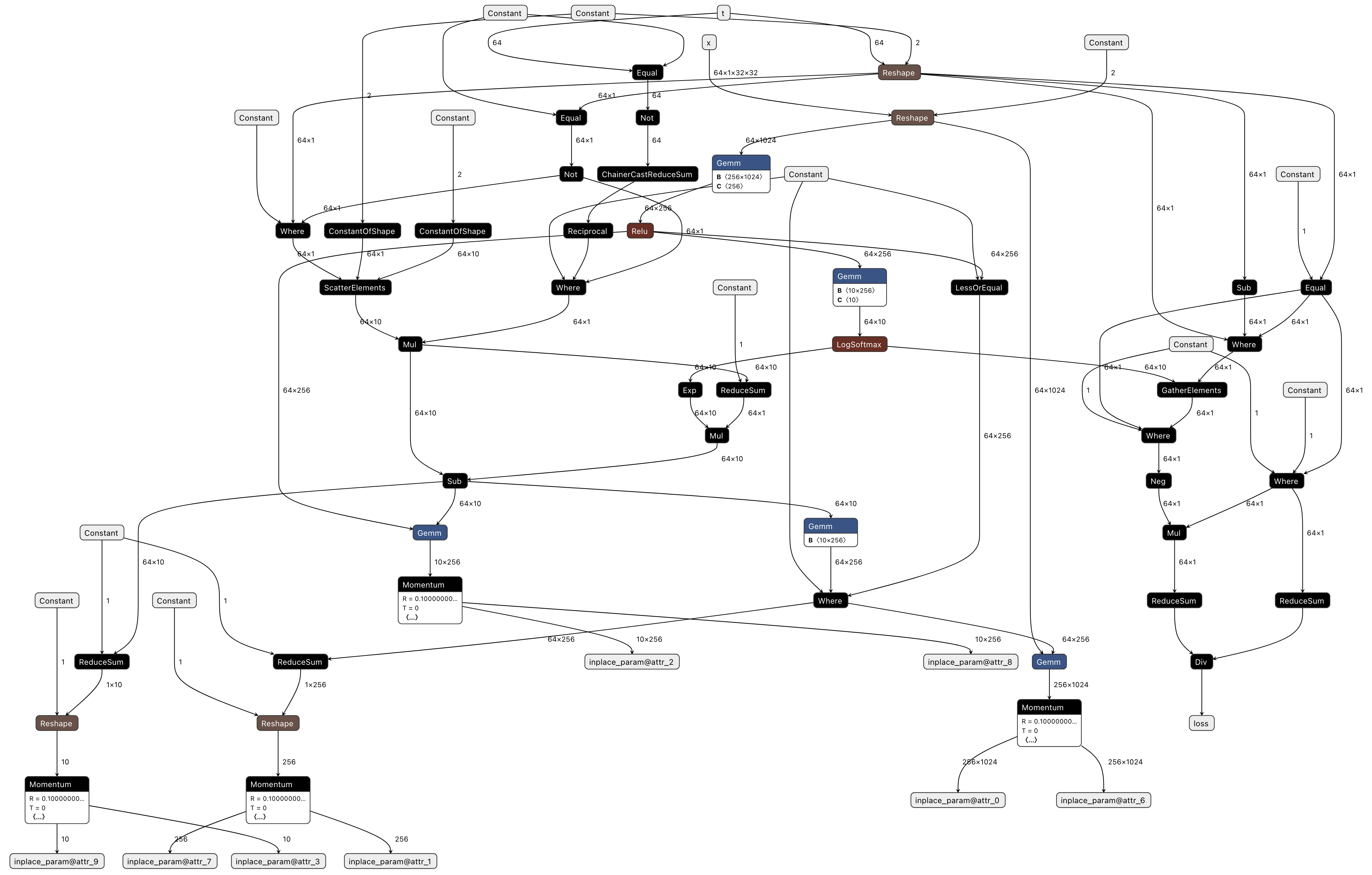
図 3.4 Visualizing pfvm.onnx (Compiled ONNX)
Forward のみだった推論処理単体と比べ、 Backward と Optimizer の処理も加わるため、グラフが非常に大きくなっていることがわかります。また、Backward や Optimizer の処理は元プログラムの実装に含まれないことが多く、各ノードとの対応付けを取るのも簡単ではありません。そのため、最低限 Forward 側が正しく動作することを確かめたうえで、Backward や Optimizer の処理を加えることをおすすめします。
さて、一見学習が正常に進み Loss が下がっている様子でも、学習結果のチェックポイントを検証すると、 Accuracy が十分に下がっていないケースがあります。この場合、モデルや Optimzier 内部の torch.Tensor が Context に登録されておらず、 Context.synchronize してもデバイス上での変更内容が反映されていないことが原因かもしれません。この仕組みについては パラメータをContextへ登録 や オプティマイザの内部バッファをContextへ登録 にも説明があります。
mncore2:auto での動作確認
最後に --device オプションに mncore2:auto を指定して、 train_step が MN-Core 2 で動くか確かめてみましょう。最終的な Accuracy は pfvm:cpu のものと異なる可能性がありますが、これは各オペレータの実装が異なるためで、数値が基準を超えていれば問題ありません。
MNCoreClassifier 自体はモデルとしては決して大きいものではありませんが、 MNGraph 中のオペレータの個数は 100 を優に超えてしまうため、 ONNX として可視化して実装との対応付をとるのは難しくなってきます。そのため、 MNGraph の内容について確認したい場合は l3ir.txt を見るのが推奨されています。