1. はじめに
シンプルな PyTorch プログラムを題材に、MLSDK の基本的な仕様について紹介します。
1.1. 事前準備
MN-Core を PyTorch から使用する を参考にワークスペースを作成してください。次に JupyterLab にアクセスし、新規 Notebook を作成します。Notebook 上でも同様に gpfn3-smi を実行する際は、先頭に ! を足してからコードセルを実行します。
Jupyter Notebook 上で gpfn3-smi list を実行する例:
!gpfn3-smi list
MN-Core 2 ボードが正常に認識されていれば 0: mnc2p28s0 のような文字列が出力されます。先頭の 0 は Device Index で、0から順にデバイスの数だけ対応付けられます。後ろの mnc2 から始まる文字列 (mnc2p28s0) は、システムの認識する Device Nameです。
1.2. ディレクトリ構造
ClusterWorkspacePreset カスタムリソース から default を選択してワークスペースを作成した場合、ディレクトリ構成は以下のようになっています。
/
├── root/ # Home directory
└── opt/pfn/pfcomp/
├── licenses/ # License files
├── fx2onnx/ # Common component of MN-Core SDK
├── pfvm/ # Common component of MN-Core SDK
├── mncl/ # HPCSDK (to be released)
└── codegen/ # Compiler core implementations
├── MLSDK/
│ ├── examples/ # Code examples
│ ├── src/ # MLSDK interfaces
│ └── ...
├── build/ # Libraries, executable files, and envvar configurations
├── preset_options/ # Compiler options for codegen (e.g. O1.json)
└── python_trainer/ # MLSDK core implementations
JupyterLab の Launcher 経由で作成した Notebook などは、デフォルトでは /root/ 以下に保存されています。これに対して MN-Core SDK において必要なファイルは /opt/pfn/pfcomp/ 以下に存在することに注意してください。
MLSDK とは別に、以降の説明で頻出する codegen というものがあります。これは MN-Core シリーズ専用のコンパイラ兼ランタイムに相当するもので、 MLSDK が内部的に python trainer を呼び出し、その python trainer が内部的に codegen のライブラリを呼び出す、という構成になっています。本資料では基本的に MLSDK として出している機能について説明しますが、コンパイラ本体に言及する場合は codegen の名前を使うことがあります。
1.3. サンプルプログラムを実行する
2つのベクトルの加算を題材に MLSDK API を使ってみましょう。まず、 torch.Tensor である変数 x と y を加算 (+) してその結果を出力する関数 add を考えます。
1def add(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
2 return x + y
これを MLSDK API を使って書き換えると、以下のようなプログラムになります。
1import torch
2from mlsdk import CacheOptions, Context, MNDevice, storage
3
4
5def run_add():
6 device = MNDevice("mncore2:auto")
7 context = Context(device)
8 Context.switch_context(context)
9
10 def add(input: dict[str, torch.Tensor]) -> dict[str, torch.Tensor]:
11 x = input["x"]
12 y = input["y"]
13 return {"out": x + y}
14
15 sample = {"x": torch.randn(3, 4), "y": torch.randn(3, 4)}
16
17 compiled_add = context.compile(
18 add,
19 sample,
20 storage.path("/tmp/add_two_tensors"),
21 options={"float_dtype": "float"},
22 cache_options=CacheOptions("/tmp/add_two_tensors_cache"),
23 )
24 result = compiled_add({"x": torch.ones(3, 4), "y": torch.ones(3, 4)})
25 result_on_cpu = result["out"].cpu()
26 print(f"{result_on_cpu=}")
27 assert torch.allclose(result_on_cpu, torch.ones(3, 4) * 2)
28
29
30if __name__ == "__main__":
31 run_add()
このプログラムを実行する前に、必要な環境変数 (LD_PRELOAD と PYTHONPATH) を設定する必要があります。これらの設定ファイルは /opt/pfn/pfcomp/codegen/build/ 以下にあり、 source コマンドで読み込むことで反映されます。
Notebook ユーザーの場合:
!source /opt/pfn/pfcomp/codegen/build/codegen_preloads.sh
!source /opt/pfn/pfcomp/codegen/build/codegen_pythonpath.sh
Terminal ユーザーの場合:
$ source /opt/pfn/pfcomp/codegen/build/codegen_preloads.sh
$ source /opt/pfn/pfcomp/codegen/build/codegen_pythonpath.sh
これで実行する準備が整ったため、上記の add.py を実行してみます。コンパイルメッセージの後に、以下の結果が出力されていれば実行に成功しています。各 API の詳細については、次の節で説明します。
result_on_cpu=tensor([[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.]])
ちなみに、環境変数の設定と実行については /opt/pfn/pfcomp/codegen/examples/exec_with_env.sh スクリプトを使うことでまとめて行えます。引数全体をまとめて exec するため、 python3 も同時に指定する必要があるのに注意します。また、 MLSDK 環境では python が python3.X へのエイリアスになっていないため、 python3 を使うようにしてください。
Terminal での使用例:
$ cd /opt/pfn/pfcomp/codegen/examples/
$ ./exec_with_env.sh python3 add.py
1.4. サンプルプログラムの解説
1.4.1. デバイス指定
5def run_add():
6 device = MNDevice("mncore2:auto")
7 context = Context(device)
mlsdk.MNDevice は使用するデバイス、もしくは代替の実行環境を指定するためのクラスです。構築した段階ではデバイスをロックしておらず、後述する mlsdk.CompiledFunction の内部でロックします。
引数として有効な値は以下の通りです。
"mncore2:" に "auto" もしくは Device Index を結合したもの
mncore2 はデバイスに MN-Core 2 を使用することを意味し、 auto はロックされていないデバイスを自動的に選びます。auto の代わりに Device Index を用いることも出来ますが、デバイス ID は使用できません。
"mncore2:auto", "mncore2:0"
注釈
複数のプロセスが同時に同じデバイスを使用する場合、ロックが成功するまで各プロセスは待機します。待機時間が一定の秒数 (600秒) を超えるとタイムアウトとして異常終了するため、 Device Index の重複はなるべく避けるか、 auto の使用を推奨します。
"emu2"
emu2 とは MN-Core 2 の動作を再現したエミュレータを意味します。エミュレータはホスト上の CPU で動作するため、 Device Index の指定は出来ません。
"emu2"
"pfvm:" に "cpu" もしくは "cuda" を結合したもの
PFVM (pfvm) は PyTorch プログラムをトレースして計算グラフを構築・最適化し、様々な実行環境で計算処理をするためのコンポーネントです。対象とする実行環境には、ホスト上の CPU (cpu) や使用可能であれば GPU (cuda) があります。同じく CPU 上で動作する emu2 と異なり、 cpu や cuda では PyTorch の C++ API を呼んで計算処理しているため、動作が比較的高速という特徴があります。また、 cuda に関しては mncore2 と同様に Device Index を指定可能です。
"pfvm:cpu", "pfvm:cuda", "pfvm:cuda:0"
ちなみに MN-Core 2 を使用する際にも PFVM を経由しています (ただし pfvm:mncore2 のような指定は出来ません)。詳細については Ecosystem を参照してください。
1.4.2. Contextによるデータ同期
6 device = MNDevice("mncore2:auto")
7 context = Context(device)
8 Context.switch_context(context)
mlsdk.Context はプログラム中の torch.Tensor とデバイス上のテンソルを関連付け、ホストとデバイスの両方からのデータアクセスを制御するためのクラスです。
構築された context は内部に専用のレジストリを持ち、そこに計算に必要な torch.Tensor を登録できます。add.py のサンプルプログラムでは登場しませんが、 例えば torch.nn.Module で作成したモデルを Context で扱う場合、 parameters や buffers (他に必要に応じて optimizer state) を登録します。更に mlsdk.Context.switch_context() で context をアクティブにすることにより、登録された torch.Tensor の内容をデバイスからアクセス可能にします。この際、ホストからデバイスへのデータコピーは必要なタイミングで自動的に行われます。
次に、後述する mlsdk.CompiledFunction (compiled_add) の呼び出しによって計算結果がデバイス上に出力されます。これはホスト上では MN-Core 2 を使用する場合 mlsdk.TensorProxy として得られるため、 torch.Tensor として扱うには以下の例のように mlsdk.TensorProxy.cpu() メソッドを呼び出し、明示的に計算結果の同期を行う必要があります。
24 result = compiled_add({"x": torch.ones(3, 4), "y": torch.ones(3, 4)})
25 result_on_cpu = result["out"].cpu()
26 print(f"{result_on_cpu=}")
注釈
"mncore2:auto" を使用する今回の例では TensorProxy として出力が得られますが、 "pfvm:cuda" を代わりに使う場合などは直接 torch.Tensor が得られます。いずれの場合でも .cpu() を呼ぶことで Python プログラムから直接扱うことが出来るため、デバイスに依存しない API になっています。
余談: 複数の Context を使い分ける
examples/ にはそのような例は未実装ですが、複数の Context を構築して使い分けるケースがあります。例えばモデルの学習と推論を連続して行いたい場合、モデル内部の torch.Tensor は共有したいですが、推論専用の最適化は別にかけたいことがあります。つまり各 torch.Tensor に対応するテンソルをどのようにデバイス上で持つかが学習時と推論時で変わるため、それぞれに Context を作ると切り替えに便利です。Context.switch_context を呼ぶことで元の Context に対応するデータはホストに移動し、変更後の Context に対応するデータがデバイス上に読み込まれます。
1.4.3. 関数のコンパイル
17 compiled_add = context.compile(
18 add,
19 sample,
20 storage.path("/tmp/add_two_tensors"),
21 options={"float_dtype": "float"},
22 cache_options=CacheOptions("/tmp/add_two_tensors_cache"),
23 )
mlsdk.Context.compile() は対象の関数 (add) 、入力のサンプル (sample) と保存先のディレクトリ (storage.path("/tmp/add_two_tensors")) を受け取り、 mlsdk.CompiledFunction を返す API です。これら3つの他にもオプションやフラグを指定することも可能で、この例では通常のオプション (options) とキャッシュ用のオプション (cache_options) を指定しています。
function=add
10 def add(input: dict[str, torch.Tensor]) -> dict[str, torch.Tensor]:
11 x = input["x"]
12 y = input["y"]
13 return {"out": x + y}
コンパイル対象の関数は Callcable[[Dict[str, Tensor]], Dict[str, Tensor]] の型であることが要求されます。各 Dict のキーは計算グラフの入出力の名前に相当するため、省略や重複は出来ず空文字列の指定も受け付けません。また、引数に含まれていない変数を関数内部で参照した場合、コンパイル時の値で固定されます。そのため、関数呼出しの度に値が更新される変数は全て torch.Tensor として引数に加える必要があります。
inputs=sample
このように、 Context.compile とは関数処理を静的な計算グラフに変換する処理です。各 torch.Tensor の次元や数値型も事前に確定させたいため、その参考として sample を受け取ります。この例では torch.randn を使って sample を定義していますが、コンパイルの時点ではその値そのものは使いません。そのため、コストの大きいテンソルの初期化を避けるために torch.empty も使用可能です。
sample = {"x": torch.empty(3, 4), "y": torch.empty(3, 4)}
また、 compiled_add の入力とする値をサンプルとしても問題ありません。add.py ではサンプルと入力で torch.Tensor の値が異なるケースを題材にしていますが、以下の例のように同じ値が使えます。
sample = {"x": torch.ones(3, 4), "y": torch.ones(3, 4)}
...
result = compiled_add(sample)
codegen_dir=storage.path("/tmp/add_two_tensors")
codegen_dir と呼ばれる、コンパイル結果を保存するディレクトリのパスを指定します。mlsdk.storage.path() の返り値は pathlib.Path であるため、引数に直接ディレクトリのパスを指定することもできます。
一度 add.py の処理を動かしている場合、 /tmp/add_two_tensors の内容を確認することが出来ます。ファイル名に .zst がつくものは Zstandard 形式で圧縮されています。
注釈
MLSDK のバージョンやコンパイル対象によって、一部の内容は異なる可能性があります。
options={"float_dtype": "float"}
コンパイル時にコンパイラの挙動について指定するオプションで、 Dict[str, str] の型が期待されます。この例では float_dtype について指定しており、コンパイル時点で torch.float32 (dtype が初期値) であるような torch.Tensor を MN-Core 2 で扱う際に float を使うよう指示しています。float_dtype には float の他にも double, mixed, half などが指定でき、指定しない場合の初期値は mixed となっています。mixed の詳細については mlsdk.Context.compile() の options の説明文を参照してください。
コンパイルオプションの詳細は コンパイルオプション を参照してください。
cache_options={"/tmp/add_two_tensors_cache"}
mlsdk.CacheOptions を引数に取り、コンパイル結果をどのように保存し再利用するのかを指定します。この例では保存先のディレクトリ (/tmp/add_two_tensors_cache) のみを指定していますが、他にも GPFNApp, ONNX, codegen cache のどれを保存するかについても指定可能です。
GPFNApp
/tmp/add_two_tensors にある model.app (もしくは model.app.zst) が GPFNApp と呼ばれるもので、MN-Core 2 用のアセンブリコードに加えて動作に必要な情報を付加したファイルです。GPFNApp は dump_gpfnapp というツールを使うことで、その内容を確認できます。
$ /opt/pfn/pfcomp/codegen/build/integration/dump_gpfnapp /tmp/add_two_tensors/model.app
target_name: GPFN3
inputs:
x: DRAM@0-16/Float(3,4 PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} alias_base=null torch_dtype=Float layout_kind=MNCore)
y: DRAM@16-32/Float(3,4 PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} alias_base=null torch_dtype=Float layout_kind=MNCore)
outputs:
out: DRAM@32-48/Float(3,4 PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B])} Dirty alias_base=null torch_dtype=Float layout_kind=MNCore)
...
この情報から、以下の内容を確認できます。
各
x,y,outに対応するデータがデバイス DRAM 上のどのアドレスに存在するか (e.g.DRAM@0-16)それぞれのデータ型が何か (e.g.
/Float)どのように Local Memory へマッピングされているのか (e.g.
PadLayout{(3,4)/((3:1), (1:1, 2_W:1, 4_PE:1); B@[MAB,L1B,L2B]))
ONNX
/tmp/add_two_tensors にある model.onnx (もしくは model.onnx.zst) が ONNX フォーマットで add 関数の計算グラフを出力したものになります。Codegen Dashboard の機能で model.onnx を可視化したものが 図 1.1 です。
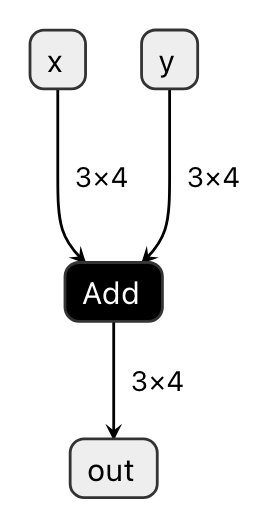
図 1.1 Visualizing model.onnx
ONNX の Add オペレータが x と y を入力として受け取り、 out を出力していることが読み取れます。この例では非常にシンプルな結果になりますが、より複雑な関数をコンパイルする場合、可視化することでそのデバッグに役立つことがあります。
codegen cache
これはコンパイルの中間生成物に相当するもので、高度な最適化を行う場合に設定します。内容は以下の2種類です。
schedule: デバイス内のデータ移動や計算カーネルの順序を決定する Scheduler の生成物simulation_result: 各計算カーネルのメモリ使用量や実行時間を推定する Node Simulation の生成物
1.4.4. CompiledFunctionを呼び出す
24 result = compiled_add({"x": torch.ones(3, 4), "y": torch.ones(3, 4)})
25 result_on_cpu = result["out"].cpu()
Context.compile の結果として得られる mlsdk.CompiledFunction (compiled_add) は、コンパイル時に受け取ったサンプルと同様の入力を受け取り、 1つ以上の mlsdk.TensorLike からなる出力を返します。TensorLike の定義は Union[torch.Tensor, TensorProxy] で、 .cpu() といった共通した API に限定して呼ぶことで、実態がどちらであっても Python プログラムからは同様に扱えます。
入力の型は Dict[str, TensorLike] であり、コンパイル時に受け取る Dict[str, Tensor] と一部の差異を除いて同様です。入力とサンプルで一致しなければならないものは、各キーと対応する Tensor もしくは TensorProxy の次元及び数値型です。ただし、 TensorProxy については同一 Context 内で対応する Tensor の情報が参照されます。計算グラフの各入力名に対応するキーが存在しない、もしくは対応する Tensor の情報が異なる場合、以下のようなメッセージを出力して終了します。
AssertionError: y is not in inputs.
terminate called after throwing an instance of 'std::runtime_error'
what(): shape '[3, 4]' is invalid for input of size 9
また、入力として使用可能な TensorProxy には別の mlsdk.CompiledFunction() の出力を使用することができる他、 mlsdk.CompiledFunction.allocate_input_proxy() で取得することも出来ます。詳細は TensorProxyを経由したデータ通信 を参照してください。
次に出力の型は Dict[str, TensorLike] であり、上述した通り .cpu() を呼ぶことで torch.Tensor として扱えます。注意点として出力データを同期する際、デバイスからホストへのデータコピーのみをしている訳ではなく、 compiled_add 処理の完了まで待機しています。これはデバイス側の処理が非同期で行われるためであり、 compiled_add 処理が完了したことを確認するには .cpu() か mlsdk.Context.synchronize() の完了を待つ必要があります。
注釈
synchronize はレジストリに登録された全ての torch.Tensor が更新され、多くのデータコピーが発生します。そのため、必要に応じて .cpu() と使い分けることを性能の観点でおすすめします。
CompiledFunction が呼び出される時、まず Context.switch_context を呼び出し、 自身が登録されている Context に切り替えます。この時同一の Context を使っている場合は何も起きませんが、複数の Context を使っている場合は意図しない性能低下の原因となるため注意が必要です。
次に計算処理を非同期実行し、その途中で MNDevice で指定されたデバイスをロックします。そのため、メモリやデバイスそのものなどのリソースが足りている限り、前の実行の同期 (終了) を待たず別の CompiledFunction() の呼び出しが可能ですが、 Device Index が同じ処理が複数実行キューに積まれている場合、それらの実行はシリアライズされます。
1.5. 発展的なトピック
MLSDK は機械学習モデルの学習・推論のための API を複数提供しており、 機械学習チュートリアル でより発展的な例を用いてそれらを説明しています。